

Some Individuals Excel At Deepseek And a few Do not - Which One Are Yo…
페이지 정보
작성자 Jonelle 작성일25-02-03 11:57 조회6회 댓글0건관련링크
본문
DeepSeek 연구진이 고안한 이런 독자적이고 혁신적인 접근법들을 결합해서, DeepSeek-V2가 다른 오픈소스 모델들을 앞서는 높은 성능과 효율성을 달성할 수 있게 되었습니다. 하지만 곧 ‘벤치마크’가 목적이 아니라 ‘근본적인 도전 과제’를 해결하겠다는 방향으로 전환했고, 이 결정이 결실을 맺어 현재 DeepSeek LLM, DeepSeekMoE, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, DeepSeek-Prover-V1.5 등 다양한 용도에 활용할 수 있는 최고 수준의 모델들을 빠르게 연이어 출시했습니다. 글을 시작하면서 말씀드린 것처럼, DeepSeek이라는 스타트업 자체, 이 회사의 연구 방향과 출시하는 모델의 흐름은 계속해서 주시할 만한 대상이라고 생각합니다. AI chip company NVIDIA noticed the most important inventory drop in its historical past, losing nearly $600 billion in stock-market worth when stocks dropped 16.86% in response to the DeepSeek news. Information included DeepSeek chat history, again-finish data, log streams, API keys and operational particulars. This knowledge, mixed with pure language and code knowledge, is used to proceed the pre-training of the DeepSeek-Coder-Base-v1.5 7B model. But I additionally read that if you happen to specialize models to do less you may make them great at it this led me to "codegpt/deepseek-coder-1.3b-typescript", this particular model could be very small by way of param rely and it's also primarily based on a deepseek ai-coder model however then it is nice-tuned using only typescript code snippets.
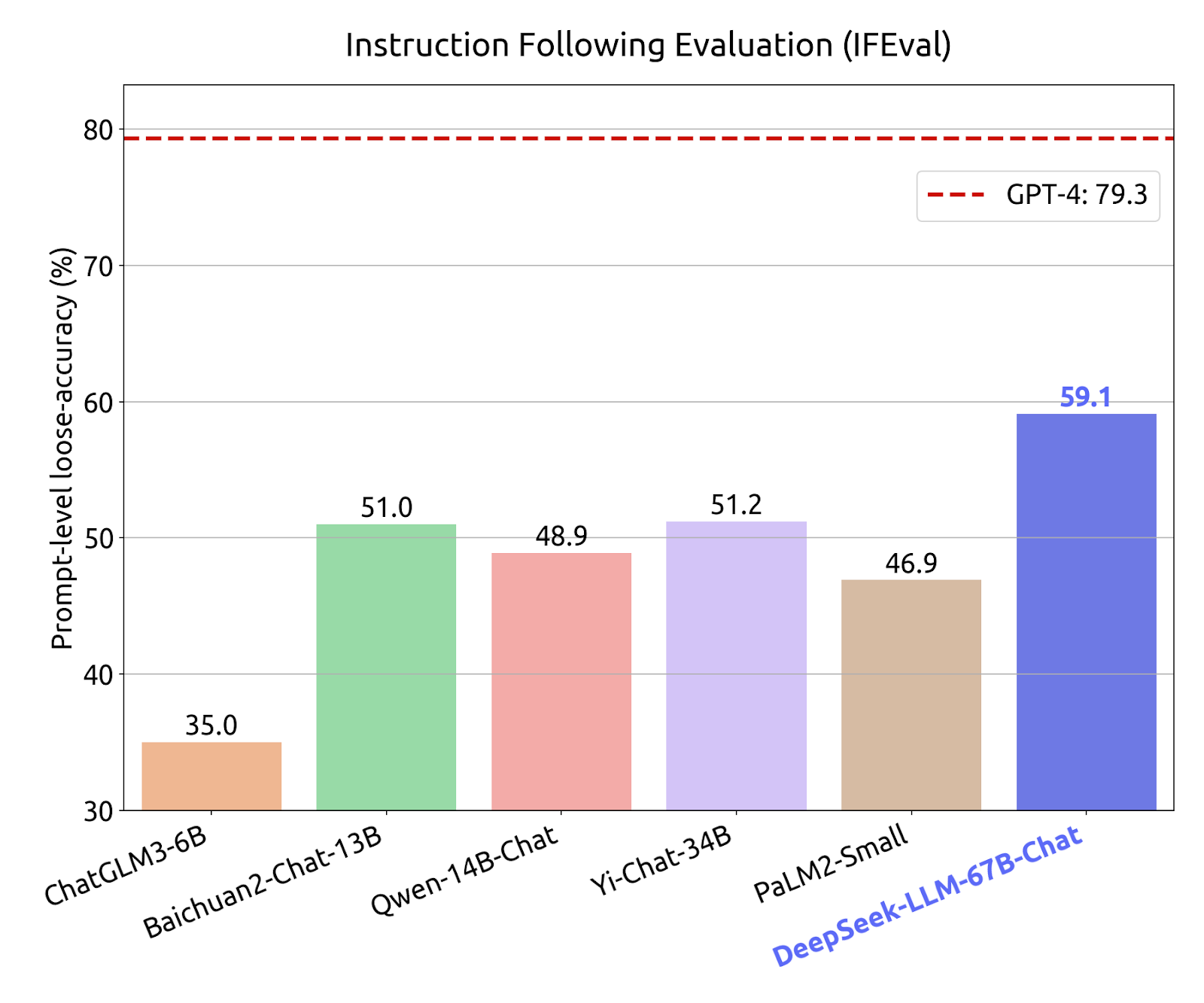
The paper introduces DeepSeekMath 7B, a big language model that has been pre-trained on an enormous amount of math-associated knowledge from Common Crawl, totaling a hundred and twenty billion tokens. First, they gathered a massive quantity of math-associated information from the web, including 120B math-related tokens from Common Crawl. DeepSeek maps, screens, and gathers knowledge across open, deep seek internet, and darknet sources to supply strategic insights and data-driven evaluation in vital matters. We provide accessible information for a variety of needs, including evaluation of manufacturers and organizations, competitors and political opponents, public sentiment among audiences, spheres of influence, and extra. LoLLMS Web UI, a terrific internet UI with many fascinating and distinctive options, including a full mannequin library for easy mannequin selection. Could you might have extra benefit from a larger 7b model or does it slide down an excessive amount of? So for my coding setup, I use VScode and I found the Continue extension of this specific extension talks on to ollama without much setting up it also takes settings on your prompts and has help for multiple models depending on which process you are doing chat or code completion. Hermes Pro takes benefit of a particular system immediate and multi-turn perform calling construction with a new chatml function with a view to make function calling dependable and simple to parse.
Some specialists fear that the government of China may use the AI system for overseas affect operations, spreading disinformation, surveillance and the event of cyberweapons. A common use case in Developer Tools is to autocomplete based on context. The important thing innovation on this work is the use of a novel optimization technique referred to as Group Relative Policy Optimization (GRPO), which is a variant of the Proximal Policy Optimization (PPO) algorithm. Second, the researchers introduced a new optimization method referred to as Group Relative Policy Optimization (GRPO), which is a variant of the well-identified Proximal Policy Optimization (PPO) algorithm. It could be attention-grabbing to discover the broader applicability of this optimization technique and its impact on other domains. This research represents a significant step ahead in the field of large language models for mathematical reasoning, and it has the potential to impression numerous domains that depend on superior mathematical expertise, similar to scientific research, engineering, and schooling. Despite these potential areas for further exploration, the overall method and the results presented in the paper signify a big step forward in the field of giant language fashions for mathematical reasoning. The research represents an necessary step ahead in the continuing efforts to develop massive language fashions that can successfully tackle complicated mathematical problems and reasoning tasks.
If you beloved this information along with you wish to be given more info with regards to ديب سيك i implore you to pay a visit to the web site.
댓글목록
등록된 댓글이 없습니다.


