

You can Thank Us Later - three Causes To Stop Eager about Deepseek
페이지 정보
작성자 Raymundo 작성일25-02-16 10:20 조회5회 댓글0건관련링크
본문
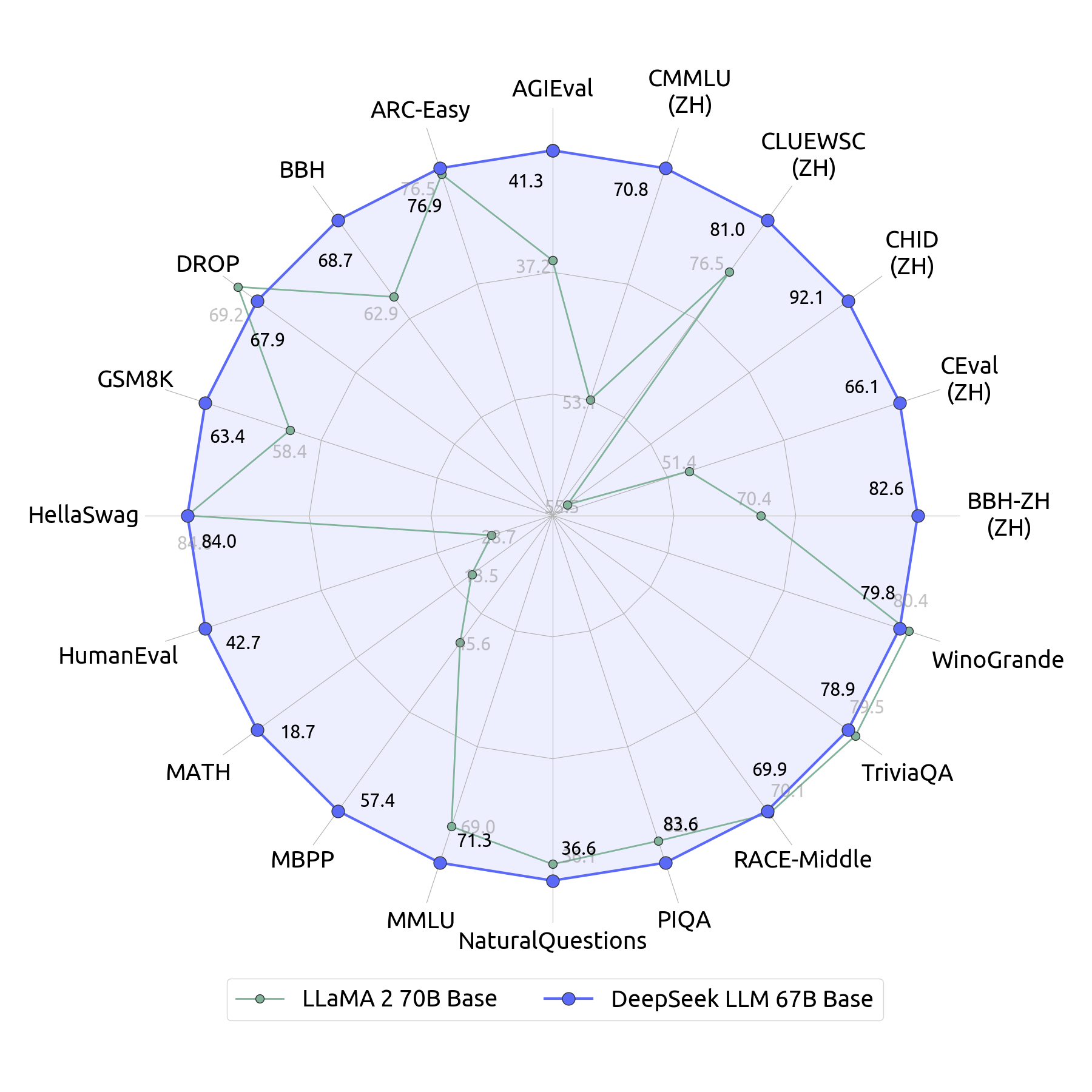 The DeepSeek workforce writes that their work makes it potential to: "draw two conclusions: First, distilling more highly effective fashions into smaller ones yields glorious outcomes, whereas smaller models counting on the massive-scale RL mentioned in this paper require monumental computational energy and will not even obtain the efficiency of distillation. We can iterate this as much as we like, although DeepSeek v3 solely predicts two tokens out during training. This allows them to make use of a multi-token prediction objective during training as an alternative of strict subsequent-token prediction, they usually exhibit a performance enchancment from this alteration in ablation experiments. Its flexibility permits builders to tailor the AI’s performance to suit their specific wants, offering an unmatched degree of adaptability. However, the DeepSeek v3 technical report notes that such an auxiliary loss hurts model performance even when it ensures balanced routing. A well-liked methodology for avoiding routing collapse is to pressure "balanced routing", i.e. the property that every knowledgeable is activated roughly an equal number of instances over a sufficiently large batch, by adding to the training loss a time period measuring how imbalanced the knowledgeable routing was in a selected batch. A critical problem with the above method of addressing routing collapse is that it assumes, with none justification, that an optimally skilled MoE would have balanced routing.
The DeepSeek workforce writes that their work makes it potential to: "draw two conclusions: First, distilling more highly effective fashions into smaller ones yields glorious outcomes, whereas smaller models counting on the massive-scale RL mentioned in this paper require monumental computational energy and will not even obtain the efficiency of distillation. We can iterate this as much as we like, although DeepSeek v3 solely predicts two tokens out during training. This allows them to make use of a multi-token prediction objective during training as an alternative of strict subsequent-token prediction, they usually exhibit a performance enchancment from this alteration in ablation experiments. Its flexibility permits builders to tailor the AI’s performance to suit their specific wants, offering an unmatched degree of adaptability. However, the DeepSeek v3 technical report notes that such an auxiliary loss hurts model performance even when it ensures balanced routing. A well-liked methodology for avoiding routing collapse is to pressure "balanced routing", i.e. the property that every knowledgeable is activated roughly an equal number of instances over a sufficiently large batch, by adding to the training loss a time period measuring how imbalanced the knowledgeable routing was in a selected batch. A critical problem with the above method of addressing routing collapse is that it assumes, with none justification, that an optimally skilled MoE would have balanced routing.
DeepSeek’s methodology essentially forces this matrix to be low rank: they decide a latent dimension and categorical it because the product of two matrices, one with dimensions latent times model and one other with dimensions (number of heads · On this architectural setting, we assign multiple question heads to every pair of key and value heads, effectively grouping the question heads together - therefore the identify of the strategy. The basic concern is that gradient descent just heads within the path that’s locally best. Gradient descent will then reinforce the tendency to choose these experts. To avoid this recomputation, it’s efficient to cache the relevant internal state of the Transformer for all past tokens and then retrieve the results from this cache when we'd like them for future tokens. The outcomes reveal high bypass/jailbreak charges, highlighting the potential risks of those rising attack vectors. However, when our neural community is so discontinuous in its habits, even the high dimensionality of the issue area may not save us from failure.
The problem with that is that it introduces a quite ailing-behaved discontinuous operate with a discrete image at the center of the model, in sharp contrast to vanilla Transformers which implement continuous input-output relations. The elemental problem with methods equivalent to grouped-question consideration or KV cache quantization is that they involve compromising on model quality in order to reduce the scale of the KV cache. Methods such as grouped-question attention exploit the possibility of the identical overlap, however they accomplish that ineffectively by forcing consideration heads that are grouped collectively to all reply similarly to queries. DeepSeek can handle buyer queries effectively, offering prompt and accurate responses. Being Chinese-developed AI, they’re subject to benchmarking by China’s internet regulator to make sure that its responses "embody core socialist values." In DeepSeek’s chatbot app, for instance, R1 won’t answer questions about Tiananmen Square or Taiwan’s autonomy. Small enterprise homeowners are already utilizing DeepSeek to handle their basic buyer questions without hiring further employees. The basic idea is the following: we first do an peculiar ahead go for subsequent-token prediction.
 The naive technique to do this is to simply do a forward cross including all past tokens every time we wish to generate a new token, but that is inefficient because those previous tokens have already been processed earlier than. Free DeepSeek v3 is altering the way in which we use AI. As we'd in a vanilla Transformer, we use the ultimate residual stream vector to generate subsequent token probabilities via unembedding and softmax. They accomplish this by turning the computation of key and value vectors from the residual stream into a two-step course of. Each skilled has a corresponding knowledgeable vector of the same dimension, and we resolve which consultants will grow to be activated by looking at which ones have the best inner products with the current residual stream. The key statement here is that "routing collapse" is an excessive state of affairs the place the likelihood of each individual expert being chosen is both 1 or 0. Naive load balancing addresses this by making an attempt to push the distribution to be uniform, i.e. each expert ought to have the identical probability of being selected. For some selection, let’s look at the identical example however with Fliki - one other AI presentation generator that includes avatars and advanced results.
The naive technique to do this is to simply do a forward cross including all past tokens every time we wish to generate a new token, but that is inefficient because those previous tokens have already been processed earlier than. Free DeepSeek v3 is altering the way in which we use AI. As we'd in a vanilla Transformer, we use the ultimate residual stream vector to generate subsequent token probabilities via unembedding and softmax. They accomplish this by turning the computation of key and value vectors from the residual stream into a two-step course of. Each skilled has a corresponding knowledgeable vector of the same dimension, and we resolve which consultants will grow to be activated by looking at which ones have the best inner products with the current residual stream. The key statement here is that "routing collapse" is an excessive state of affairs the place the likelihood of each individual expert being chosen is both 1 or 0. Naive load balancing addresses this by making an attempt to push the distribution to be uniform, i.e. each expert ought to have the identical probability of being selected. For some selection, let’s look at the identical example however with Fliki - one other AI presentation generator that includes avatars and advanced results.
댓글목록
등록된 댓글이 없습니다.


